
Explora. Visualiza. Modela. Una mejor perspectiva empieza con Stata.
Rápido. Preciso. Fácil de usar. Stata es un paquete de software completo e integrado que cubre todas sus necesidades de ciencia de datos: manipulación de datos, visualización, estadísticas e informes automatizados.
Adquirir o actualizar Stata
Gestión de Datos
Stadísticas
Gráficos
¿Por qué Stata?
Rápido. Preciso. Fácil de usar. Stata es un paquete de software completo e integrado que cubre todas sus necesidades de ciencia de datos: manipulación de datos, visualización, estadísticas e informes automatizados.
|
|
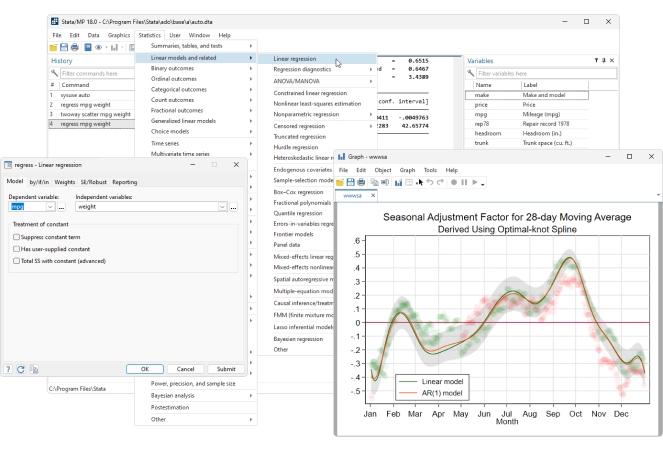
Domine sus datos
Las funciones de gestión de datos de Stata le brindan control total.
|
|
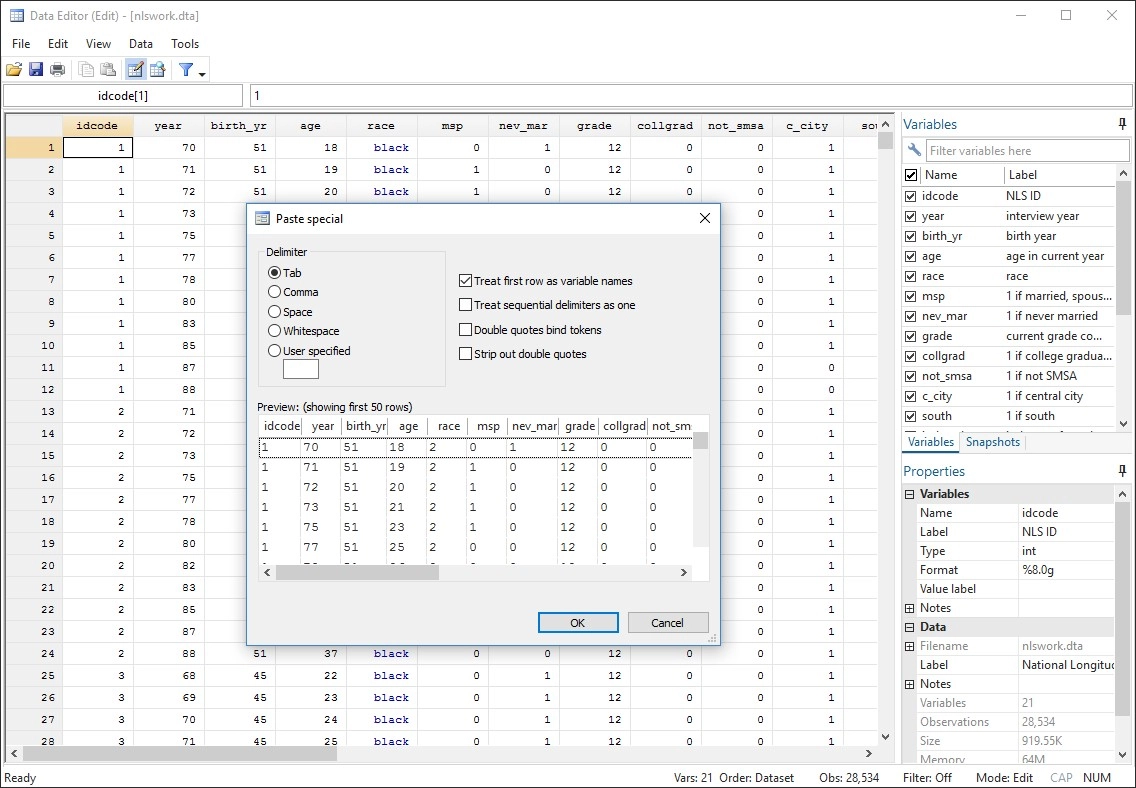
Gráficos de calidad de publicación
Stata facilita la generación de gráficos con un estilo distintivo y con calidad de publicación.
Puedes apuntar y hacer clic para crear un gráfico personalizado. O puedes escribir scripts para producir cientos o miles de gráficos de forma reproducible.
Exporte gráficos a EPS o TIFF para publicación, a PNG o SVG para la web, o a PDF para visualización.
Con el Editor de gráficos integrado, puede hacer clic para cambiar cualquier aspecto de su gráfico o para agregar títulos, notas, líneas, flechas y texto.
Informes automatizados
Todas las herramientas que necesitas para automatizar el informe de tus resultados.
- Documento de Markdown dinámico
- Crear documentos de Word
- Crear documentos PDF
- Crear archivos de Excel
- Tablas personalizables
- Esquemas para gráficos
- Word, HTML, PDF, SVG, PNG
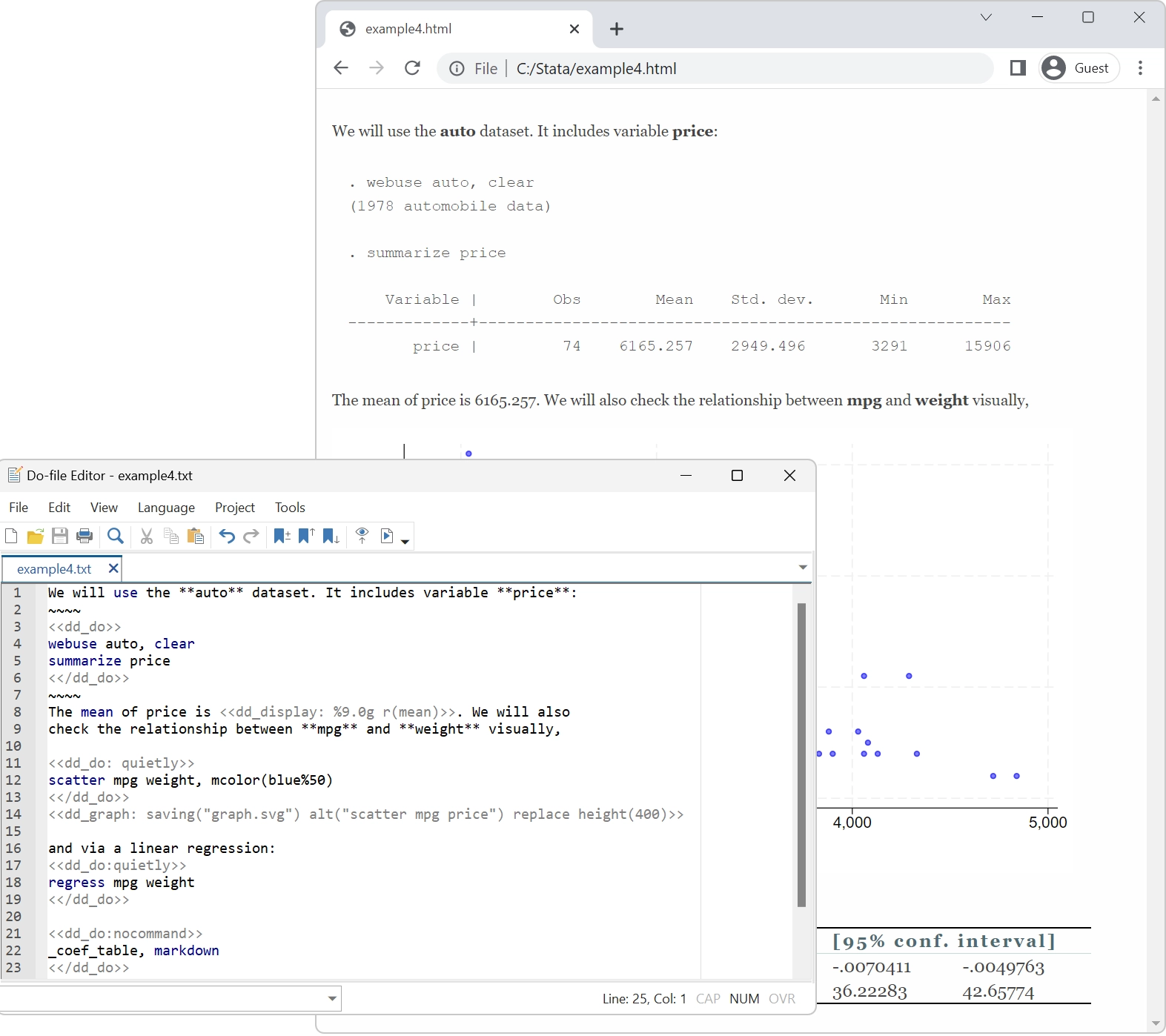
Investigación verdaderamente reproducible
Mucha gente habla de investigación reproducible. Stata se ha dedicado a ello durante más de 40 años.
Constantemente añadimos nuevas funciones; incluso hemos modificado radicalmente elementos del lenguaje. No importa. Stata es el único paquete estadístico con control de versiones integrado. Si escribiste un script para realizar un análisis en 1985, ese mismo script seguirá ejecutándose y produciendo los mismos resultados hoy. Cualquier conjunto de datos que creaste en 1985, podrás leerlo hoy. Y lo mismo ocurrirá en 2050. Stata podrá ejecutar cualquier cosa que hagas hoy.
Nos tomamos muy en serio la reproducibilidad.
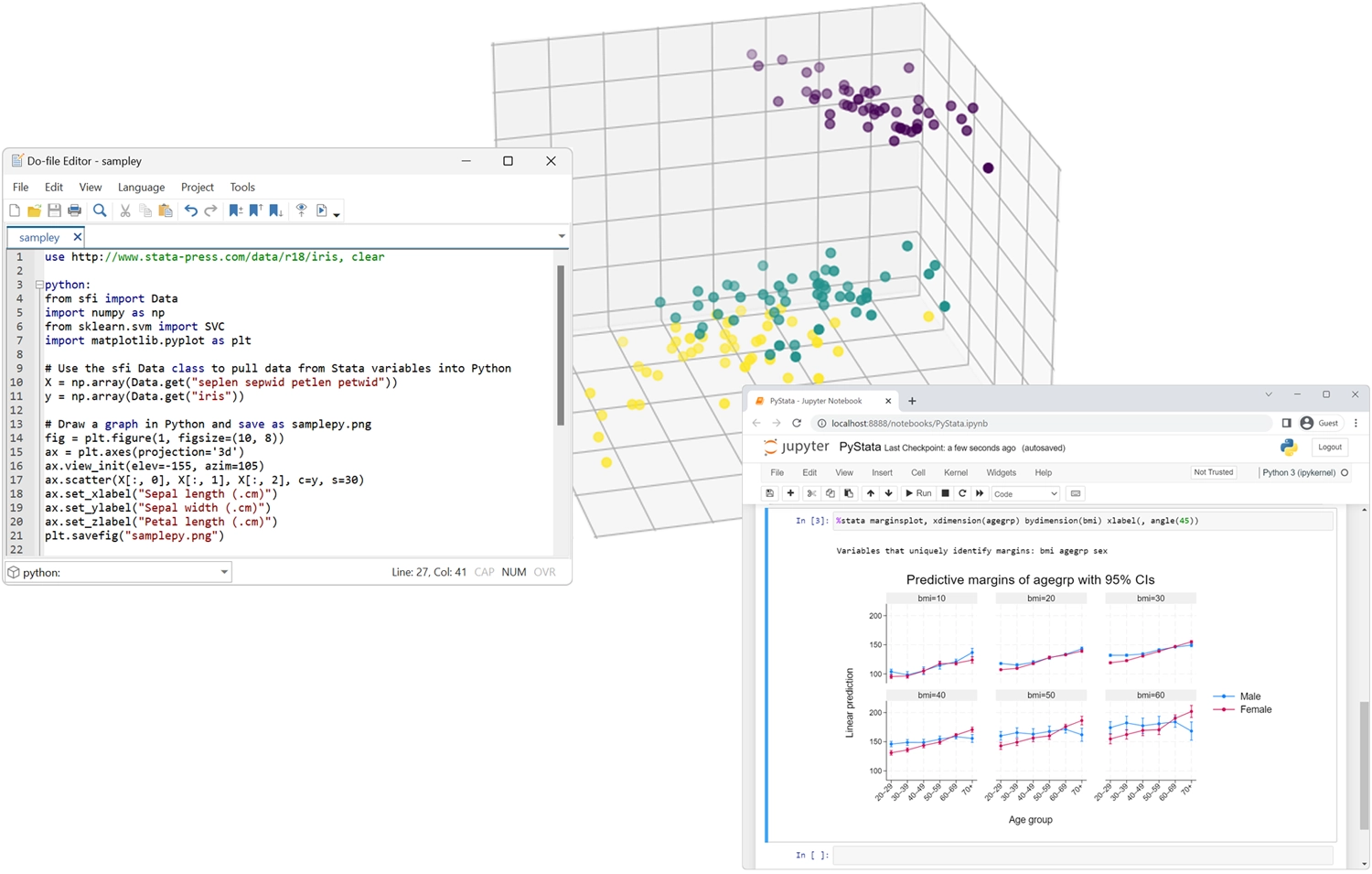
PyStata - Integración de Python
Invoque Python de forma interactiva o incorpore Python en su código Stata.
Invocar Stata desde Python y llamar al código Stata desde entornos IPython.
Utilice Stata dentro de Jupyter Notebook.
Transfiera datos y resultados sin problemas entre Stata y Python.
Utilice los análisis de Stata desde Python.
Utilice cualquier paquete de Python dentro de Stata
- Matplotlib y seaborn para visualización
- Beautiful Soup and Scrapy para el web scraping
- NumPy y pandas para análisis numérico
- TensorFlow y scikit-learn para el aprendizaje automático
- Y mucho más
Documentación real
Cuando llega el momento de realizar sus análisis o comprender los métodos que está utilizando, Stata no lo deja abandonado a su suerte ni lo obliga a pedir libros para aprender cada detalle.
Cada una de nuestras funciones de gestión de datos está completamente explicada y documentada, y se muestra en la práctica con ejemplos reales. Cada estimador está completamente documentado e incluye varios ejemplos con datos reales, con explicaciones reales sobre cómo interpretar los resultados. Los ejemplos le proporcionan los datos para que pueda trabajar con Stata e incluso ampliar los análisis. Le ofrecemos una guía de inicio rápido para cada función, mostrando algunos de los usos más comunes. ¿Desea obtener más detalles? Nuestras secciones de Métodos y fórmulas proporcionan los detalles de lo que se calcula, y nuestras Referencias le indican aún más información.
Stata es un paquete grande y, por lo tanto, cuenta con mucha documentación: más de 19 000 páginas en 36 manuales. Pero no te preocupes, escribe "ayuda con mi tema" y Stata buscará en sus palabras clave, índices e incluso en paquetes aportados por la comunidad para ofrecerte toda la información que necesitas sobre tu tema. Todo está disponible directamente en Stata.
De confianza
No solo programamos métodos estadísticos, los validamos.
Los resultados que obtiene de un estimador de Stata se basan en comparaciones con otros estimadores, simulaciones de Monte Carlo de consistencia y cobertura, y exhaustivas pruebas realizadas por nuestros estadísticos. Todos los productos de Stata que entregamos han superado un paquete de certificación que incluye 7,2 millones de líneas de código de prueba que generan 6 millones de líneas de salida. Certificamos cada número y fragmento de texto de esos 5,8 millones de líneas de salida.
Confiable
Durante más de 40 años, StataCorp ha sido fiel a sus usuarios, expandiendo el software Stata con nuevos métodos estadísticos y lo último en generación de informes, visualización y manipulación de datos, así como en la interfaz de usuario. Gracias a nuestra larga trayectoria de lanzamientos, nos comprometemos a proporcionar continuamente un software estable y confiable a nuestra diversa comunidad de investigadores y profesionales.
![]()
Actualizado continuamente
Mantenerse actualizado con la versión más actualizada de Stata ahora es más fácil que nunca.
StataCorp desarrolla continuamente nuevas funciones para mejorar el software Stata, desde los métodos estadísticos más recientes hasta la mejor generación de informes, visualización de datos e interfaz de usuario. Con StataNow™, se lanzan nuevas funciones desde la versión actual hasta la siguiente versión principal. Estas funciones se priorizan en el ciclo de desarrollo para que estén disponibles en cuanto estén listas y los usuarios puedan aprovecharlas de inmediato.
![]()
Fácil de usar
Mantenerse actualizado con la versión más actualizada de Stata ahora es más fácil que nunca.
Se puede acceder a todas las funciones de Stata a través de menús, diálogos, paneles de control, un editor de datos, un administrador de variables, un editor de gráficos e incluso un generador de diagramas SEM. Puede navegar por cualquier análisis con solo apuntar y hacer clic.
Si no quieres escribir comandos ni scripts, no tienes que hacerlo.
Incluso mientras apunta y hace clic, puede registrar todos sus resultados e incluirlos posteriormente en informes. Incluso puede guardar los comandos generados por sus acciones y reproducir su análisis completo posteriormente.
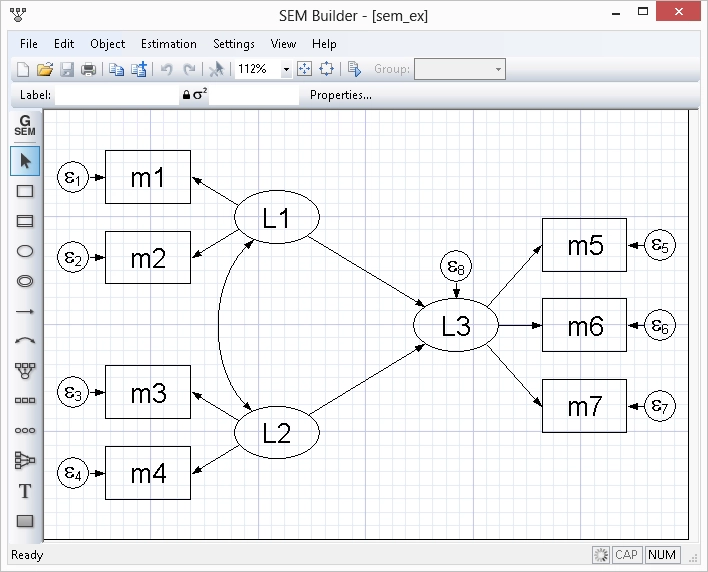
Fácil de cultivar con
Los comandos de Stata para realizar tareas son intuitivos y fáciles de aprender. Mejor aún, todo lo aprendido sobre la ejecución de una tarea puede aplicarse a otras. Por ejemplo, simplemente añada `if gender=="female"` a cualquier comando para limitar el análisis a las mujeres de la muestra. Simplemente añada `vce(robust)` a cualquier estimador para obtener errores estándar y pruebas de hipótesis robustas a muchos supuestos comunes.
La consistencia es aún más profunda. Lo aprendido sobre los comandos de gestión de datos suele aplicarse a los comandos de estimación, y viceversa. También existe un conjunto completo de comandos de posestimación para realizar pruebas de hipótesis, formar combinaciones lineales y no lineales, hacer predicciones, generar contrastes e incluso realizar análisis marginales con gráficos de interacción. Estos comandos funcionan de la misma manera con prácticamente cualquier estimador.
La secuenciación de comandos para leer y depurar datos, realizar pruebas estadísticas y estimaciones, y finalmente informar los resultados, es fundamental para una investigación reproducible. Stata facilita el acceso a este proceso a todos los investigadores.
![]()
Fácil de automatizar
Todos tenemos tareas que realizamos constantemente: crear un tipo específico de variable, generar una tabla específica, realizar una secuencia de pasos estadísticos, calcular un RMSE, etc. Las posibilidades son infinitas. Stata cuenta con miles de procedimientos integrados, pero es posible que tenga tareas relativamente únicas o que desee realizar de una manera específica.
Si ha escrito un script para realizar su tarea en un conjunto de datos determinado, es fácil transformar ese script en algo que pueda usarse en todos sus conjuntos de datos, en cualquier conjunto de variables y en cualquier conjunto de observaciones.
![]()
Fácil de ampliar
Algunas de las cosas que automatizas pueden ser tan útiles que quieras compartirlas con tus colegas o incluso ponerlas a disposición de todos los usuarios de Stata. Es muy fácil. Con solo un poco de código, puedes convertir un script de automatización en un comando de Stata. Un comando que admite las funciones estándar de los comandos oficiales de Stata. Un comando que se puede usar de la misma manera que los comandos oficiales.
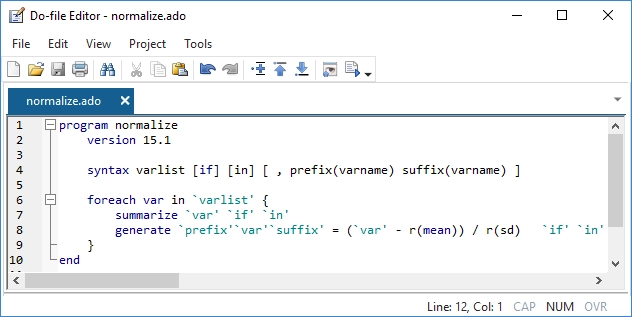
Programación avanzada
Stata también incluye un lenguaje de programación avanzado: Mata.
Mata tiene las estructuras, punteros y clases que esperas en tu lenguaje de programación y agrega soporte directo para la programación matricial.
Aunque no es necesario programar para usar Stata, es reconfortante saber que un lenguaje de programación rápido y completo es parte integral de Stata. Mata es tanto un entorno interactivo para manipular matrices como un entorno de desarrollo completo que puede producir código compilado y optimizado. Incluye funciones especiales para procesar datos de panel, realiza operaciones con matrices reales o complejas, ofrece soporte completo para programación orientada a objetos y está completamente integrado con todos los aspectos de Stata. Stata también cuenta con una completa integración con Python, lo que permite aprovechar toda la potencia de Python directamente desde el código de Stata.
Stata también tiene PyStata, que proporciona una integración completa con Python, lo que le permite aprovechar todo el poder de Python directamente desde su código Stata y aprovechar todo el poder de Stata desde su código Python.
Stata incluso te permite incorporar complementos de C, C++ y Java en tus programas mediante una API nativa para cada lenguaje. ¡Incluso puedes incrustar código Java directamente en tu código de Stata!
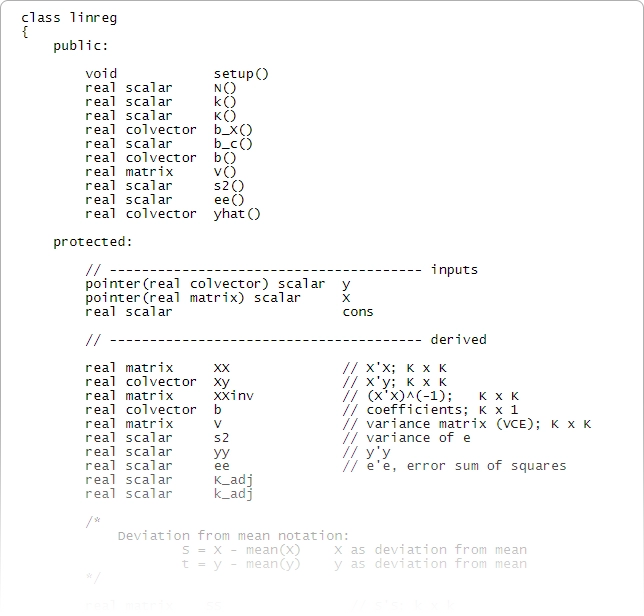

Funciones aportadas por la comunidad
Stata es tan programable que los desarrolladores y usuarios agregan nuevas funciones todos los días para responder a las crecientes demandas de los investigadores actuales.
Con las capacidades de Internet de Stata, se pueden instalar nuevas funciones y actualizaciones oficiales a través de Internet con un solo clic.
Soporte técnico de clase mundial
Todos los usuarios registrados de la versión actual de Stata (Stata 19) pueden acceder a soporte técnico gratuito. Si aún no ha registrado su copia de Stata, complete el formulario de registro en línea.
Contamos con un equipo dedicado de programadores y estadísticos expertos en Stata para responder a sus preguntas técnicas. Desde soluciones complejas de gestión de datos hasta cómo lograr que su gráfico tenga la apariencia perfecta, y desde la explicación de un error estándar robusto hasta la especificación de su modelo multinivel, tenemos las respuestas.
![]()
Compatible con varias plataformas
Stata funciona en ordenadores Windows, Mac y Linux/Unix; sin embargo, nuestras licencias no son específicas de ninguna plataforma. Esto significa que si tiene una portátil Mac y una de escritorio Windows, no necesita dos licencias independientes para ejecutar Stata. Puede instalar su licencia de Stata en cualquiera de las plataformas compatibles. Los conjuntos de datos, programas y otros datos de Stata se pueden compartir entre plataformas sin necesidad de traducción. También puede importar conjuntos de datos de otros paquetes estadísticos, hojas de cálculo y bases de datos de forma rápida y sencilla.
Ampliamente utilizado
Utilizado por investigadores durante más de 40 años, Stata proporciona todo lo que necesita para la ciencia de datos: manipulación de datos, visualización, estadísticas e informes automatizados.
Seleccione su disciplina y vea cómo Stata puede trabajar para usted.
Novedades de Stata 19
Lleve su investigación más lejos con las nuevas funciones de Stata 19.
Stata 19 tiene algo para todos. A continuación, enumeramos los aspectos más destacados de esta versión. Stata 19 es único porque la mayoría de las nuevas funciones pueden ser utilizadas por investigadores de todas las disciplinas.
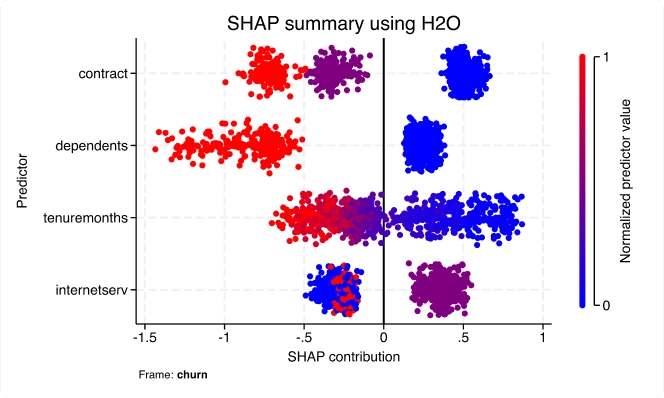
Aprendizaje automático mediante H2O: árboles de decisión de conjunto
Con la nueva suite h2oml, utilice el aprendizaje automático a través de H2O para extraer información valiosa de los datos cuando los modelos estadísticos tradicionales resultan insuficientes. Los métodos de aprendizaje automático se utilizan a menudo para resolver problemas de investigación y empresariales centrados en la predicción.
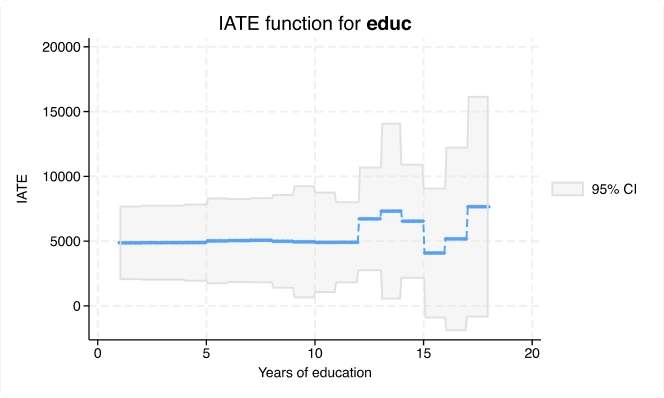
Efectos del tratamiento promedio condicional (CATE)
Con el nuevo comando cate, puede ir más allá de estimar un efecto general del tratamiento para estimar efectos individualizados o específicos del grupo que aborden este tipo de preguntas de investigación.

Efectos fijos de alta dimensión (HDFE)
Absorba no solo una sino múltiples variables categóricas de alta dimensión en sus modelos lineales y lineales de efectos fijos con la opción absorb() de los comandos areg y xtreg.
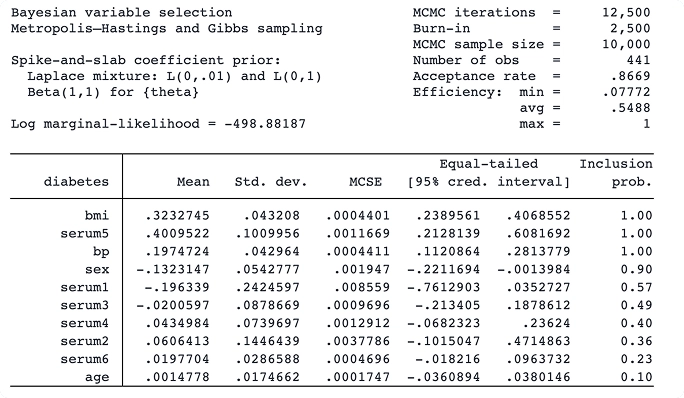
Selección de variables bayesianas para regresión lineal
Con el nuevo comando bayesselect, puede realizar la selección bayesiana de variables para la regresión lineal. Este enfoque ofrece una interpretación intuitiva y una inferencia estable, considerando la incertidumbre del modelo.
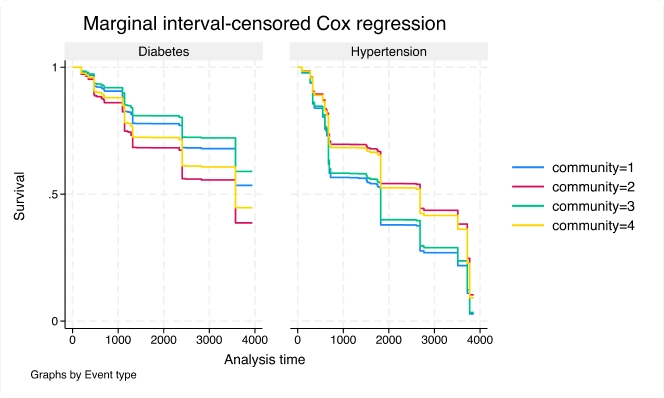
Modelos marginales de PH de Cox para datos de eventos múltiples censurados por intervalos
Utilice el nuevo comando stmgintcox para analizar datos de eventos múltiples censurados por intervalo.
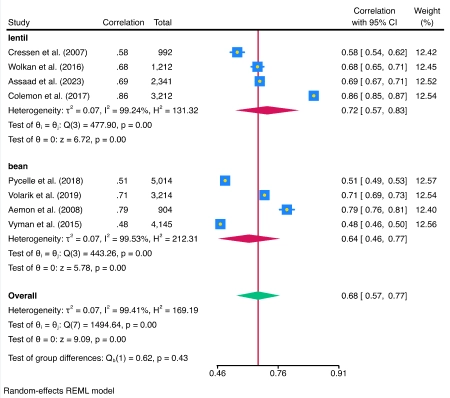
Metaanálisis de correlaciones
La suite meta ahora admite el metanálisis (MA) de un coeficiente de correlación. Se admiten todas las funciones estándar de metanálisis, como los diagramas de bosque y el análisis de subgrupos.

Modelo de efectos aleatorios correlacionados (CRE)
¿Necesita estimaciones de coeficientes de covariables invariantes en el tiempo en su modelo de datos de panel? Con xtreg, cre , ahora puede ajustar un modelo de efectos aleatorios correlacionados.
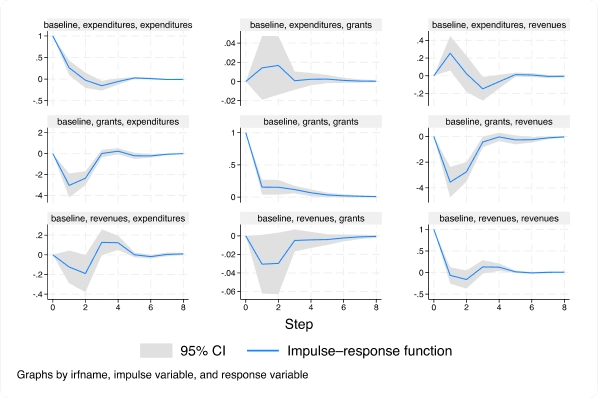
Modelo autorregresivo vectorial (VAR) de datos de panel
Con el nuevo comando xtvar, ahora puede ajustar un modelo vectorial autorregresivo (VAR) de datos de panel para analizar las trayectorias de variables relacionadas cuando observa múltiples unidades o paneles a lo largo del tiempo.
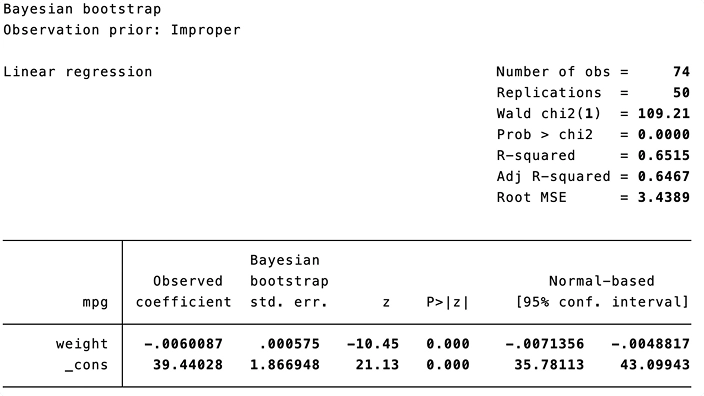
Bootstrap bayesiano y pesos de réplica
Puede usar el nuevo prefijo bayesboot para realizar un bootstrap bayesiano de las estadísticas generadas por comandos oficiales y aportados por la comunidad. El bootstrap bayesiano puede incorporar información previa para obtener estimaciones de parámetros más precisas.
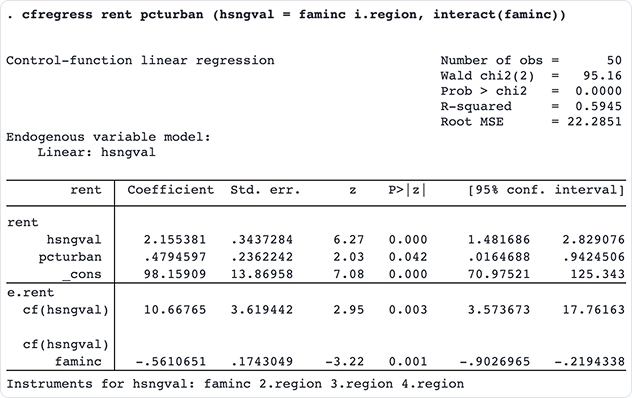
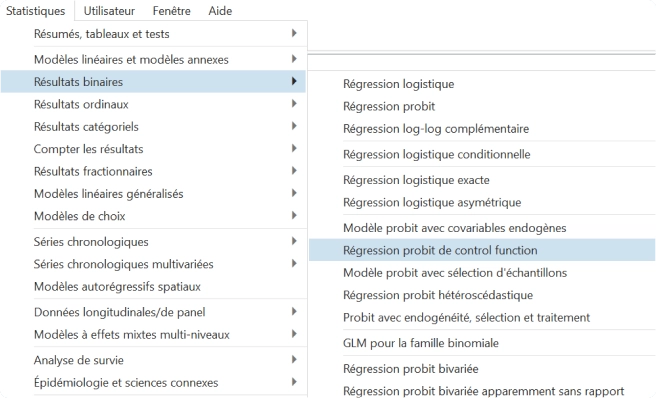
Modelos lineales y probit de función de control
Ajuste modelos lineales y probit de función de control con los nuevos comandos cfregress y cfprobit. Los modelos de función de control ofrecen un enfoque más flexible a los métodos tradicionales de variables instrumentales (VI) al incluir variables endógenas.
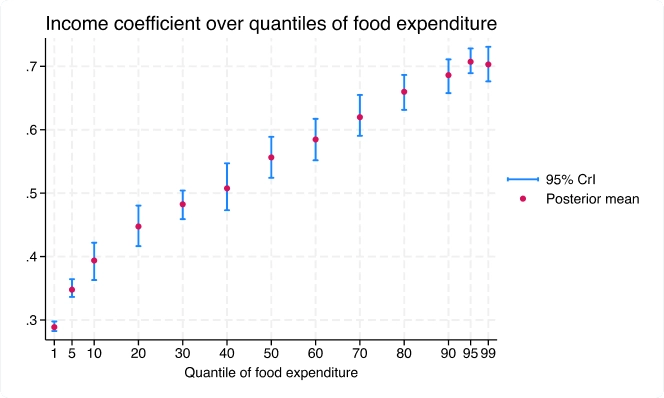
Regresión cuantil bayesiana mediante verosimilitud asimétrica de Laplace
El nuevo comando bayes:qreg se ajusta a la regresión cuantil bayesiana. El marco bayesiano proporciona distribuciones posteriores completas para los coeficientes de la regresión cuantil, lo que permite una inferencia exhaustiva.

Inferencia robusta a instrumentos débiles
Utilice el nuevo comando estat weakrobust para realizar inferencias confiables en regresores endógenos.
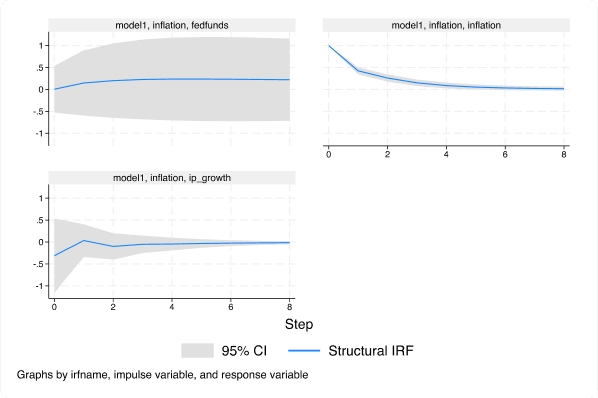
Modelos autorregresivos vectoriales estructurales (SVAR) mediante variables instrumentales
Con el nuevo comando ivsvar, puede utilizar instrumentos en lugar de restricciones de corto plazo para estimar efectos causales dinámicos.
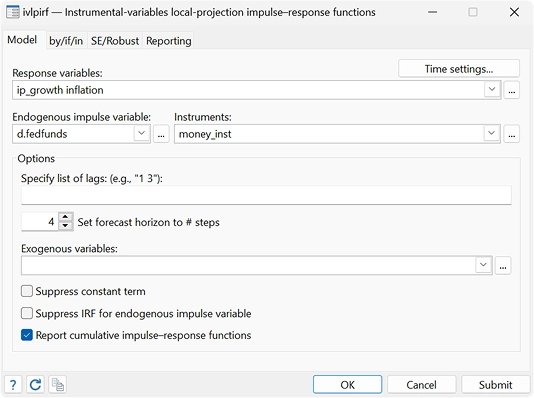
IRF de proyección local de variables instrumentales
Con el nuevo comando ivlpirf, puede tener en cuenta la endogeneidad al utilizar proyecciones locales para estimar efectos causales dinámicos.

Prueba de especificación de Mundlak
Utilice el nuevo comando de postestimación estat mundlak después de xtreg para elegir entre modelos de efectos aleatorios (RE), efectos fijos (FE) o efectos aleatorios correlacionados (CRE) incluso con errores estándar robustos a grupos, bootstrap o jackknife.

Estadísticas de comparación de modelos de clases latentes
Con el nuevo comando lcstats, puede utilizar estadísticas como la entropía y una variedad de criterios de información para ayudarlo a determinar la cantidad adecuada de clases.
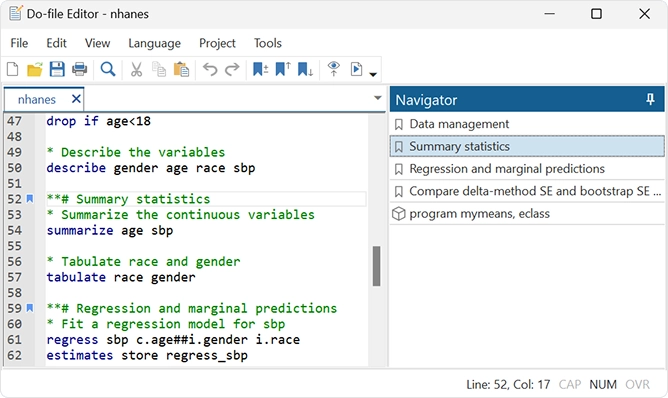
Editor de archivos Do: autocompletado, plantillas y más
El editor de archivos Do tiene las siguientes novedades: Autocompletado de nombres de variables, macros y resultados almacenados; Mejoras en el plegado de código; Marcadores temporales y permanentes; Plantillas, pestañas y panel de navegación.
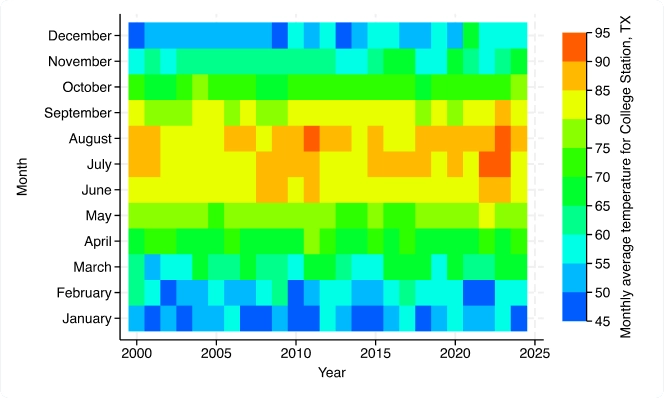
Gráficos: CI de gráficos de barras, mapas de calor y más
Nuevas características gráficas: Mapas de calor (dos vías); Gráfico de rango y puntos con picos limitados (dos vías); Gráfico de rango y puntos con picos (dos vías); Etiquetado mejorado, CI y control de agrupaciones para gráficos de barras, gráficos de puntos y diagramas de caja; Colores por variable para más gráficos.
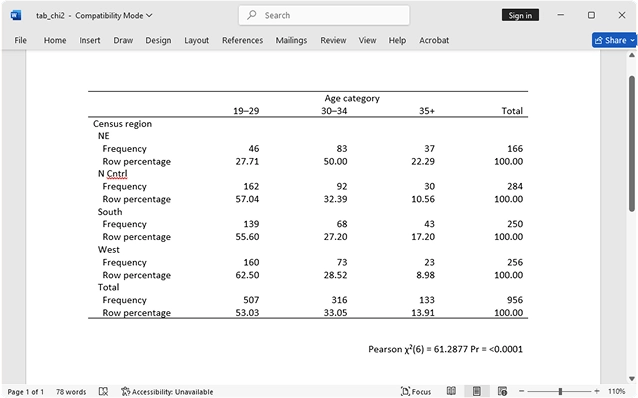
Tablas: tabulaciones más sencillas, exportación y más
Cree y personalice fácilmente tablas con títulos, notas y opciones de exportación. El comando "tabla" es una herramienta flexible para crear tabulaciones, tablas de estadísticas de resumen, tablas de resultados de regresión y más.
Stata en francés
Los menús, diálogos y demás elementos de Stata ahora se pueden mostrar en francés. Si el idioma de su ordenador es francés (fr), Stata usará automáticamente la configuración en francés.
Presentamos StataNow™
Nuevas funciones lanzadas al ritmo de Stata. Con StataNow, siempre tendrás las últimas funciones.
StataNow es una versión de lanzamiento continuo de Stata, que ofrece nuevas funciones tan pronto como están listas y garantiza que los usuarios siempre tengan acceso a la versión más reciente de Stata.
Directamente del desarrollo a ti. Con StataNow, siempre tienes acceso a las últimas funciones.
Requisitos del sistema
| OS | Mac con Windows 10 y Apple Silicon y macOS 10.13 o posterior para Mac con procesadores Intel |
|---|---|
| Processor | Apple Silicon, procesador Intel o AMD (Core i3 o superior) |
| Memory | Stata/MP > 4GB, Stata/SE > 2GB, and Stata/BE 1GB |
| Hard Drive | 4 GB |
| Graphics | ATI Radeon 8500 or Nvidia GeForce 4 or higher video card |
Stata en su investigación
Utilizado por cientos de miles de investigadores durante más de 40 años, Stata proporciona todo lo que necesita para la ciencia de datos: manipulación de datos, visualización, estadísticas e informes reproducibles.
Seleccione su disciplina y vea cómo Stata puede trabajar para usted.
El Boletín
-
Más
-
 Más
MásESG Ratings in 2026: Correction, Not Collapse
-
 Más
MásGreenflation or Transformation? Unpacking Energy Prices in the Transition Era
-
 Más
MásIs the World Heading for a Soft Landing in 2026?
-
 Más
MásA Generation at Risk: The Realities of Youth Unemployment in Europe and the UK
-
 Más
MásRebuilding Economies After Natural Disasters: What Does The Data Say?








